Researchers in Japan develop a reinforcement learning framework that enables spoken dialogue systems to acquire new vocabulary efficiently while minimizing user burden.
Osaka, Japan – Researchers at The University of Osaka have developed a mechanism that allows spoken dialogue systems to learn new words through conversation without overwhelming users with repetitive questions. By optimizing when to ask a question using reinforcement learning, the system can achieve efficient knowledge acquisition with minimal interruptions.
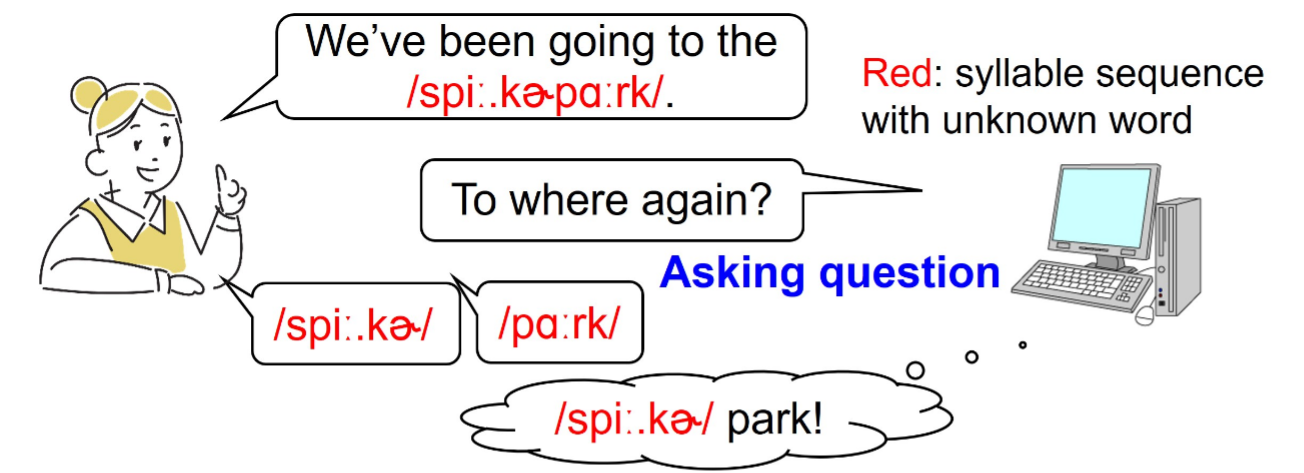
Current dialogue systems often fail to understand words not included in their training data, such as nicknames, local slang, or newly coined terms. While large language models can handle common vocabulary from the Web, they still struggle with group-specific expressions used in everyday conversation. Conventional approaches rely on repeatedly asking users for clarification, which risks frustrating them and disrupting the dialogue flow.
To address this challenge, the SANKEN team at The University of Osaka formulated the learning process as a stream-based active learning problem. Their method enables the system to decide dynamically whether to ask the user for confirmation. By introducing reinforcement learning extensions—including pseudo-labeling (self-learning) and budget-aware decision-making—the system can efficiently update its vocabulary with far fewer user queries. Simulation experiments confirmed that this approach improves word segmentation performance while reducing the number of questions asked.

This breakthrough paves the way for more natural, user-friendly dialogue systems. In the future, when such systems are part of our homes, they will be able to learn family-specific nicknames and unique expressions, becoming more familiar and trusted companions rather than intrusive tools.
“Large language models are trained on massive text data, but they cannot adapt to the unique words and expressions of each household through interaction,” explains Professor Kazunori Komatani. “Our work takes a step toward dialogue systems that learn personally, making them closer companions in daily life.”
Title: Learning to Ask Efficiently in Dialogue: Reinforcement Learning Extensions for Stream-based Active Learning
Authors: Issei Waki, Ryu Takeda, and Kazunori Komatani
Article available: https://aclanthology.org/2025.sigdial-1.34.pdf
Funded by:
Japan Society for the Promotion of Science
Japan Science and Technology Agency
Article Publication Date: 26-AUG-2025
Reference URL
Division of Information and Quantum Sciences
Department of Knowledge Science(KOMATANI Lab)
https://www.ei.sanken.osaka-u.ac.jp/en/