研究成果のポイント
- 学習データにない未知語や新語が現れた際、音声対話システムがユーザへの質問回数を押さえつつ効率よく新しい単語について学ぶ仕組みを開発
- 従来の対話システムは、対話を通じて学ぼうとすると頻繁に質問しがちだったが、「質問するかどうか」の判断基準を強化学習※1で最適化することで、少ない質問回数で効率的な学習を実現
- 各家庭に個別の対話システムが導入される時代が来たときに、会話を通じて家族独自の呼び方やニックネームを学習でき、より身近で親しみやすい存在になることが期待される
概要
大阪大学産業科学研究所の駒谷和範教授、武田龍准教授、脇一晟さん(博士前期課程修了)らの研究グループは、音声対話システムがユーザとの対話を通じて効率的に新しい知識を獲得するための仕組みを開発しました。
通常の対話システムは、学習データにない未知語や新語が現れると、正しく理解して応答することができません。大規模言語モデル(LLM)※2を用いればWeb上に出現する一般語には幅広く対応できますが、特定のグループ内でしか通じない呼称やニックネーム、新しく生まれた言葉には必ずしも対応できません。私たちの日常会話では、正式名称よりもこうした呼称が使われることが多いため、対話システムがこれらを理解できるようになることは、人間らしい自然な対話を実現するうえで不可欠です。
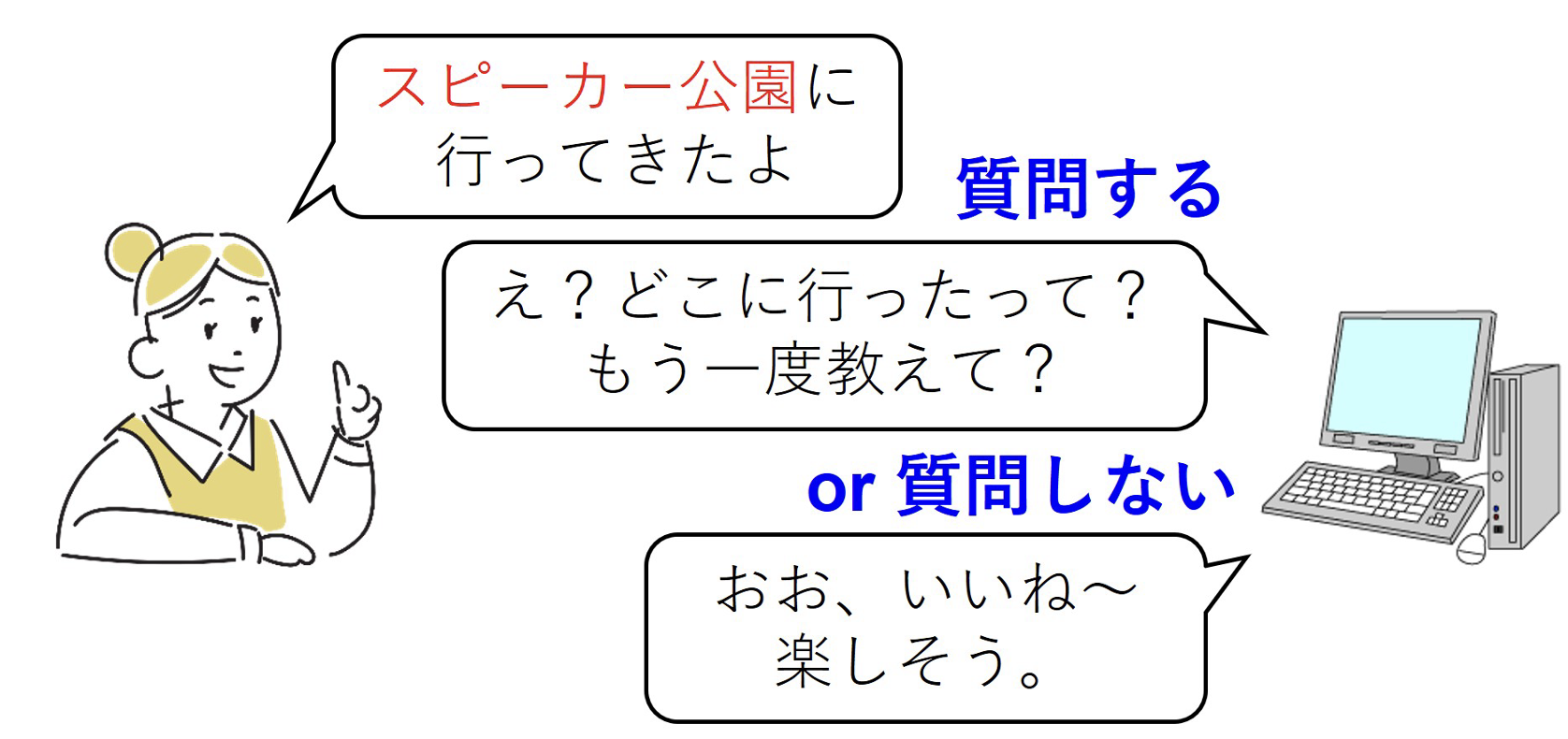
本研究では、この課題に対し、未知語について対話システムがユーザへ質問するかどうか(図1)を強化学習によって最適化することで、少ない回数の質問でも効率的に学習する枠組みを提案しました。さらに、この学習において2つの拡張を提案し、シミュレーション実験により有効性を確認しました。
これにより、ユーザ体験を損なわないように質問を行い、未知語について学習できる対話システムの実現が期待されます。
本研究成果は、フランス・アビニョンで2025年8月25日〜27日に開催された国際会議『SIGDIAL2025』で口頭発表されました。
大規模言語モデル(LLM)は既存の大量データから学習されていますが、人間との対話を通じて相手の言葉や経験から学ぶことはありません。私たちの研究グループでは、各個人や家庭に寄り添うAIを実現するため、会話を通じて独自の呼び方やニックネームを学び、身近で親しみやすい存在となることを目指しています。本研究はその第一歩です。
研究の背景
通常の対話システムは、システムの語彙に含まれない未知語や新語が現れると正しく理解して応答できません。近年広く使われつつある大規模言語モデル(LLM)を用いることでWeb上に出現する一般語には幅広く対応できるようになりましたが、特定のグループ内でしか通じない呼称やニックネーム、新しく生まれた言葉には必ずしも対応できません。例えば図1にある「スピーカー公園」は、本研究の担当者の家庭でのみ使われる呼称です。この公園には「小野原南1号公園」のような正式名称があり、大規模言語モデルは正式名称であれば理解できます。しかし、日常の会話では正式名称よりもこうした呼称が使われることが多く、これらを理解できるようにすることは、身近で親しみやすい対話システムの実現に不可欠です。
従来、このような未知語を対話中に学習させる場合、システムはユーザに頻繁に質問を繰り返しがちで、円滑な対話を妨げるという問題がありました。効率的に知識を獲得するためには、ユーザ体験を損なわず、必要なときだけ適切に質問する仕組みが求められていました。
研究の内容
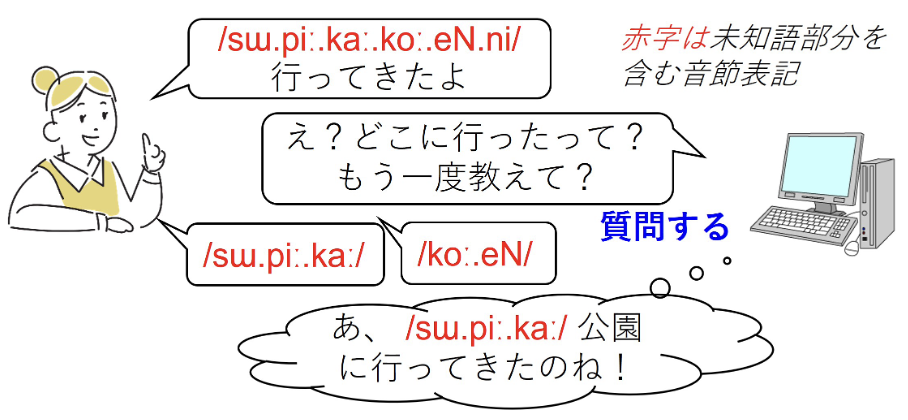
研究グループは、対話中に現れる未知語を理解するための基盤として、通常の音声認識では扱えない未知語に対応できる方法を検討しました。従来の音声認識は単語単位で行われるため、未知語や新語は学習データに含まれず正しく認識されません。そこで本研究では、音声を音節単位で認識し、その並び(音節列)から正しい単語の切れ目を推定する課題を対象としました。
この課題をストリーム型能動学習※3として定式化し、逐次的に現れるユーザ発話の音節列に対して「ユーザに質問するか/しないか」を選択する問題としました(図2)。さらに、この選択を強化学習で最適化する際に2つの拡張を行いました。1つは、システムの推定結果をそのまま学習に利用する「自己学習(擬似ラベルの利用)」であり、もう1つは残り質問回数を強化学習の状態に組み込むことで、学習の進み具合に応じて柔軟に戦略を変えられるようにした点です。シミュレーション実験の結果、これらの拡張により、少ない質問回数でも効率的に、未知語を含む音節列から単語の切れ目を学習できることを確認しました。
本研究成果が社会に与える影響(本研究成果の意義)
本研究成果により、少ない質問で効率的に、未知語など対話を通じて新しく得るべき内容を学習できる対話システムの実現が期待されます。特に、サンプル効率※4の向上は、ユーザに負担をかけずに対話を通じて知識を獲得できることを意味します。将来的には、各家庭に導入される対話システムが、会話を通じてその家庭ならではの呼び方やニックネームを学習し、より身近で親しみやすい存在となることが期待されます。
特記事項
本研究成果は、2025年8月26日(火)に国際会議 『SIGDIAL 2025』 (The 26th Annual Meeting of the Special Interest Group on Discourse and Dialogue) にて口頭発表されました。SIGDIAL(Special Interest Group on Discourse and Dialogue)は、ACL(Association for Computational Linguistics)とISCA(International Speech Communication Association)が共同で運営する対話と談話研究に関する国際コミュニティで、本国際会議を主催しています。
タイトル:“Learning to Ask Efficiently in Dialogue: Reinforcement Learning Extensions for Stream-based Active Learning”
著者名: Issei Waki, Ryu Takeda, and Kazunori Komatani
論文URL:https://aclanthology.org/2025.sigdial-1.34.pdf
なお、本研究は、JSPS科研費(JP23K28147、JP22H00536)およびJSTムーンショット型研究開発(JPMJM2011)の支援を受けて実施されました。
用語解説
※1 強化学習
試行錯誤を繰り返しながら「よりよい判断」を学んでいく学習手法。
※2 大規模言語モデル(LLM)
ChatGPTのように、大量のテキストを学習して、質問に答えたり文章を理解・生成したりできる人工知能。
※3 ストリーム型能動学習
能動学習の一種。能動学習とは、正解の付いていないデータの中から「どれを選んで人に正解を尋ねれば効率的に性能が上がるか」を考える方法。ストリーム型では、データは自由に選べるのではなく1つずつ順番に出てくるという設定で、そのたびに「人に正解を尋ねるべきかどうか」を判断する。
※4 サンプル効率
どれくらい少ないデータで効果的に学習できたかを表す指標。今回の実験では、性能の向上幅を、そのために行った質問回数で割って評価した。